
2月12日,小米雷軍通過微博泄漏,小米機器東說念主團隊厚愛開源Xiaomi-Robotics-0,一個47億參數的具身智能VLA模子。該模子遴薦Mixture-of-Transformers攙雜架構,在LIBERO、CALVIN和SimplerEnv三大仿真測試集的總共Benchmark中,與30個對比模子比較均獲適宜前最優得益。

圖片起首:小米時期
Xiaomi-Robotics-0的中樞在于通過MoT架構將視覺講話大模子與多層Diffusion Transformer解耦。VLM負責處理正常教唆與空間聯系融會,澳門新浦京DiT則通過流匹配生成高頻、流通的Action Chunk。這種聯想讓模子在揮霍級顯卡上即可完成及時推理,處分了現存VLA模子因推理延長導致真機“手腳斷層”的共性痛點。
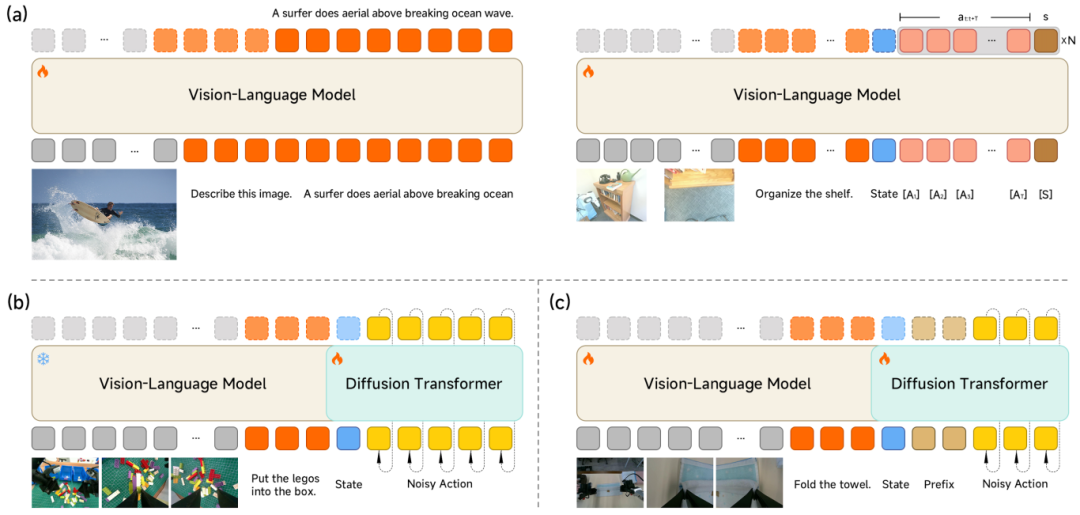
模子架構及實踐姿色:(a) VLM多模態與手腳攙雜預實踐;(b) DiT專項預實踐;(c) 打算任務后實踐;圖片起首:小米時期
實踐計謀分為兩個階段。跨模態預實踐階段引入Action Proposal機制,強制VLM在圖像清爽的同期揣摸多模態手腳離別,時時彩完成特征空間與手腳空間的對皆;隨后凍結VLM,專項實踐DiT從噪聲中收復精確手腳序列。后實踐階段的中樞是異步推理形態,使模子推理與機器東說念主運轉脫離同步斂跡。同期,Clean Action Prefix通過引入上一時期手腳輸入來保證軌跡流通性,Λ-shape Attention Mask則強制模子優先反應現時視覺反饋,進步靠近環境擾動時的反應敏捷性。
在真機部署測試中,搭載該模子的雙臂機器東說念主在積木拆解、疊毛巾等萬古序、高目田度任務中展現出相識的手眼配合才氣,同期保留了VLM原有的物體檢測與視覺問答才氣。名堂代碼、模子權重與時期文檔當今已同步上線GitHub和Hugging Face。
 備案號:
備案號: